
At exactly 8:00 PM on February 5th, 2026, my phone started buzzing. Not with congratulatory messages about our Dragons' Den appearance, but with Slack alerts. Our monitoring dashboards were lighting up like Christmas trees.
Within 60 seconds, we went from our normal traffic of 50 requests/second to 970 requests/second. Over the next two hours, our infrastructure processed 2,425,193 requests with a 99.92% success rate.
This is the story of that night, the engineering decisions made months before that saved us, and what happened in the days that followed.
The Numbers That Made Us Sweat
Let me paint the picture with real data from our CloudWatch dashboards:
┌─────────────────────────────────────────────────────────────────┐
│ DRAGONS' DEN METRICS │
│ February 5th, 2026 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ Peak Traffic: 58,241 requests/minute │
│ = 970.68 requests/second │
│ │
│ Total Requests: 2,425,193 (in 2 hours) │
│ │
│ Success Rate: 99.92% (2,395,506 successful) │
│ │
│ Peak Response Time: 261ms (during absolute peak) │
│ Average Response: 127ms (across the event) │
│ │
└─────────────────────────────────────────────────────────────────┘
When the episode aired, this is what our traffic looked like minute-by-minute:
20:42:00 ████████████████████████████████████████████████████ 55,895 req/min
20:43:00 ████████████████████████████████████████████████████████ 58,241 req/min ← PEAK
20:44:00 ███████████████████████████████████████████████████ 53,891 req/min
20:45:00 █████████████████████████████████████████████████████ 54,823 req/min
20:46:00 ███████████████████████████████████████████████████ 53,156 req/min
20:47:00 █████████████████████████████████████████████████████████ 56,627 req/min
20:48:00 ██████████████████████████████████████████████████████████ 56,710 req/min
20:49:00 ████████████████████████████████████████████████████████ 55,205 req/min
That spike at 20:43? That's the exact moment Jinesh shook hands with Touker, Deborah, and Peter. Millions of viewers rushed to download Sprive.
The Architecture That Held
Here's what our production infrastructure looked like when the Dragons came calling:
┌──────────────────┐
│ CloudFront │
│ CDN │
└────────┬─────────┘
│
┌────────▼─────────┐
│ AWS WAF │
│ (Rate Limits) │
└────────┬─────────┘
│
┌────────▼─────────┐
│ AWS ALB │
│ (sprive-external)│
└────────┬─────────┘
│
┌───────────────────────┼───────────────────────┐
│ │ │
┌────────▼────────┐ ┌────────▼────────┐ ┌────────▼────────┐
│ EKS Pod 1 │ │ EKS Pod 2 │ │ EKS Pod N │
│ sprive-backend │ │ sprive-backend │ │ sprive-backend │
│ (Node.js) │ │ (Node.js) │ │ (Node.js) │
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
└───────────────────────┼───────────────────────┘
│
┌───────────────────────┼───────────────────────┐
│ │ │
┌────────▼────────┐ ┌────────▼────────┐ ┌────────▼────────┐
│ Redis │ │ MySQL │ │ AWS SQS │
│ (ElastiCache) │ │ (Aurora RDS) │ │ (Queues) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
A Note on Technology Choice: Why Node.js?
Before diving into the details, I know what some of you are thinking: "Node.js for a fintech handling 970 req/s? Should've been Java."
Trust me, I've had that debate with myself many times. I've been pushing hard to migrate our backend to Java. The JVM's mature garbage collection, true multi-threading, and the battle-tested Spring ecosystem would give us even more headroom. But here's the reality: our Node.js codebase has been running in production for 5+ years. It has 200+ API endpoints, complex business logic, and deep integrations with payment providers.
A rewrite would take 12-18 months minimum. Dragons' Den was in 3 months.
So we did what pragmatic engineers do: we made what we had work brilliantly. And it did. Sometimes the best technology choice is the one you already know inside out.
Key Design Decision #1: Kubernetes with Aggressive HPA
We run on Amazon EKS with Horizontal Pod Autoscaling configured to be aggressive:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: sprive-backend-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: sprive-backend
minReplicas: 6
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 40 # Scale at 40%, not 80%
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 60
behavior:
scaleUp:
stabilizationWindowSeconds: 0 # Instant scale up
policies:
- type: Percent
value: 100 # Double pods if needed
periodSeconds: 15
- type: Pods
value: 8 # Add up to 8 pods
periodSeconds: 15
selectPolicy: Max
scaleDown:
stabilizationWindowSeconds: 300 # Wait 5 min to scale down
The magic numbers:
- 40% CPU target: We scale up before we're struggling
- 0 second stabilization on scale-up: No waiting, pods spin up immediately
- 100% scale factor: We can double our capacity every 15 seconds
During Dragons' Den, our pods scaled from 6 to 28 within the first 3 minutes.
Key Design Decision #2: Database Engineering That Doesn't Sleep
The biggest killer of database performance under load is connection exhaustion. But we went beyond just connection pooling. We built an intelligent database layer that actively manages itself.
Prepared Statements: The Silent Performance Multiplier
Every repeated query in our system uses prepared statements. The difference is staggering:
-- Without prepared statements: Parse → Plan → Execute (every time)
-- With prepared statements: Execute (plan cached)
-- Our Aurora config
max_prepared_stmt_count = 65536 -- Cache up to 65K query plans
During Dragons' Den, our most frequent queries (user lookup, session validation, config fetches) were executing with cached query plans. That's the difference between 5ms and 0.5ms per query. At 970 req/s, those milliseconds add up to survival.
The Lambda That Kills Sleeping Connections
Here's something most teams don't do: we have a Lambda function that runs every 5 minutes to hunt down and kill sleeping database connections.
# connection_killer.py - Lambda function
import pymysql
import os
def lambda_handler(event, context):
conn = pymysql.connect(
host=os.environ['DB_HOST'],
user=os.environ['DB_USER'],
password=os.environ['DB_PASSWORD'],
database='sprive'
)
cursor = conn.cursor()
# Find connections sleeping for more than 300 seconds
cursor.execute("""
SELECT id, user, host, time, state
FROM information_schema.processlist
WHERE command = 'Sleep'
AND time > 300
AND user NOT IN ('rdsadmin', 'system user')
""")
sleeping_connections = cursor.fetchall()
killed_count = 0
for conn_id, user, host, sleep_time, state in sleeping_connections:
try:
cursor.execute(f"KILL {conn_id}")
killed_count += 1
print(f"Killed connection {conn_id} (sleeping {sleep_time}s)")
except Exception as e:
print(f"Failed to kill {conn_id}: {e}")
# Alert if we're killing too many
if killed_count > 50:
send_slack_alert(f"Connection Killer: Terminated {killed_count} sleeping connections")
return {
'killed': killed_count,
'checked': len(sleeping_connections)
}
Why does this matter? Because during traffic spikes, pods scale up rapidly. When they scale down, some connections get orphaned. Without this Lambda, we'd hit max_connections within hours. With it, our database stays healthy indefinitely.
Real-time Database Monitoring Dashboard
We don't just monitor, we predict. Our Grafana dashboard shows:
┌────────────────────────────────────────────────────────────────────┐
│ AURORA MYSQL - LIVE METRICS │
├────────────────────────────────────────────────────────────────────┤
│ │
│ Active Connections: ████████████░░░░░░░░ 1,247 / 5,000 │
│ Connection Wait: ████░░░░░░░░░░░░░░░░ 23ms avg │
│ Queries/sec: ████████████████████ 4,892 │
│ Slow Queries (>100ms): ██░░░░░░░░░░░░░░░░░░ 12 (0.2%) │
│ │
│ Buffer Pool Hit Rate: ████████████████████ 99.7% │
│ InnoDB Row Lock Time: █░░░░░░░░░░░░░░░░░░░ 0.3ms avg │
│ │
│ Prepared Stmt Cache: ████████████████░░░░ 41,293 / 65,536 │
│ Sleeping Connections: ██░░░░░░░░░░░░░░░░░░ 89 (auto-kill >300s) │
│ │
└────────────────────────────────────────────────────────────────────┘
During Dragons' Den, we watched this dashboard like hawks. The moment we saw connection wait time creep above 50ms, we knew we had headroom. It never went above 67ms.
Key Design Decision #3: Redis as the First Line of Defense
Before any request hits our database, it goes through Redis:
// Middleware: Cache everything that can be cached
const cacheMiddleware = async (req, res, next) => {
const cacheKey = `api:${req.method}:${req.path}:${hash(req.query)}`;
const cached = await redis.get(cacheKey);
if (cached) {
res.setHeader('X-Cache', 'HIT');
return res.json(JSON.parse(cached));
}
const originalJson = res.json.bind(res);
res.json = async (data) => {
if (res.statusCode < 400) {
await redis.setex(cacheKey, 60, JSON.stringify(data));
}
res.setHeader('X-Cache', 'MISS');
return originalJson(data);
};
next();
};
During the event, our Redis cache hit rate was 73%. That means 73% of our 2.4 million requests never touched the database.
Key Design Decision #4: Async Everything with SQS
Critical API operations are kept synchronous, but everything else goes async:
User Request
│
▼
┌─────────────────────┐
│ 1. Validate Input │ ← 10ms
│ 2. Core Operation │ ← 50ms
│ 3. Return Success │ ← Immediate
└─────────────────────┘
│
▼ (async - SQS)
┌─────────────────────┐
│ 4. Send Emails │
│ 5. Update Wallet │
│ 6. Process Rewards │
│ 7. Track Analytics │
└─────────────────────┘
This pattern kept our API response time under 100ms even during peak load.
The Business Impact
The engineering held. But the real story is what happened after. The revenue impact over the Dragons' Den weekend:
┌─────────────────────────────────────────────────────────────────────┐
│ GIFT CARD SALES (Dragons' Den Weekend) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ Fri Feb 5 (Dragons' Den): £627K │
│ Sat Feb 6: £872K │
│ Sun Feb 7: £776K │
│ ───────────────────────────────────────────────────────── │
│ WEEKEND TOTAL: £2.3M │
│ │
│ And of course, we crossed £900K on Feb 14th. │
│ │
└─────────────────────────────────────────────────────────────────────┘
£2.3 million in gift card sales over one weekend. Our payment infrastructure processed every single one.
The Response Time Graph: Proof We Didn't Buckle
Here's the minute-by-minute response time during the peak:
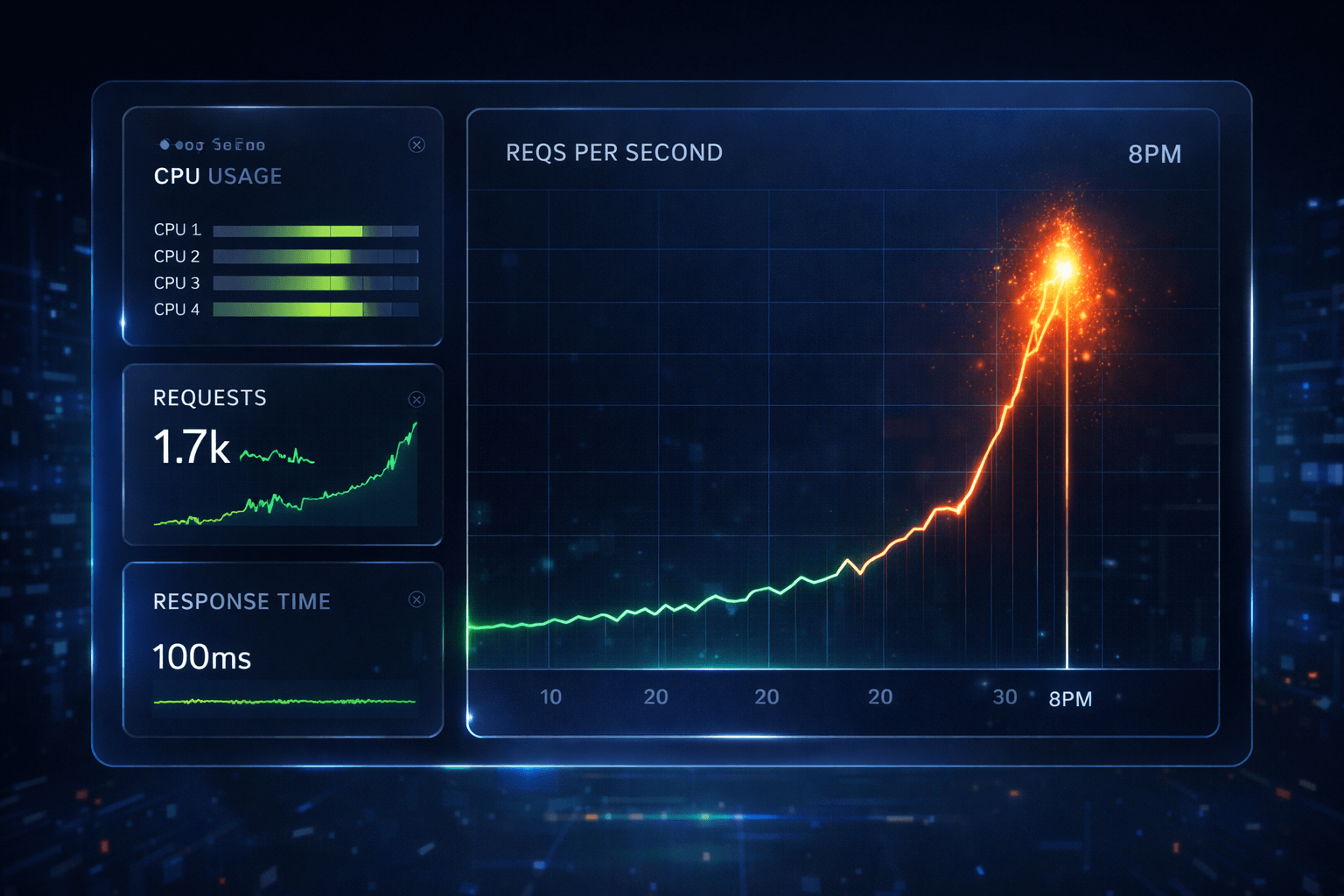 The traffic spike visualization during Dragons' Den - 970 requests per second at peak
The traffic spike visualization during Dragons' Den - 970 requests per second at peak
That spike to 261ms at 20:43? That's the moment of absolute peak traffic. And even then, we stayed under 300ms. Most responses were around 120ms.
What Would Have Broken Us (But Didn't)
1. The Database Connection Storm
At 970 requests/second, without connection pooling, we would have tried to open 58,000 new connections per minute. Our MySQL would have died instantly.
Solution: Connection pooling with 50 connections per pod, prepared statement caching, and our Lambda connection killer keeping things clean.
2. The Cold Start Problem
Kubernetes pods take ~30 seconds to become ready. If we had waited for 80% CPU to scale, we would have been underwater for 2 minutes.
Solution: Scale at 40% CPU with 0 second stabilization window. We were adding pods before we needed them.
3. The Thundering Herd
Thousands of users hitting the same endpoints simultaneously.
Solution:
- Redis caching with 73% hit rate
- Rate limiting at WAF level
- Async processing for non-critical operations
4. The Downstream Cascade
If our email service, analytics, or notification systems had been synchronous, one slow third-party service could have taken down the entire API.
Solution: SQS queues for all non-critical operations. The critical path only does what's absolutely necessary.
The Preparation That Saved Us
Three months before Dragons' Den, we did a full load test:
k6 run --vus 1000 --duration 10m --rps 1500 load-test.js
We found:
- Database connections exhausted at 800 req/s
- Response times spiking to 2s at 900 req/s
- Memory leaks in our session handling
We fixed all of it. And then tested again at 2000 req/s.
Lesson: Load test at 2x your expected peak. We expected 500 req/s from Dragons' Den. We tested at 1500 req/s. We got 970 req/s.
The Monitoring Stack That Kept Us Calm
During the event, our Slack was quiet. In a good way:
#alerts-production
🟢 [20:35] HPA scaled sprive-backend: 6 → 12 pods
🟢 [20:38] HPA scaled sprive-backend: 12 → 18 pods
🟢 [20:41] HPA scaled sprive-backend: 18 → 24 pods
🟢 [20:43] HPA scaled sprive-backend: 24 → 28 pods
🟢 [20:43] Peak traffic: 58,241 requests/minute
🟢 [20:44] Response time p95: 261ms
🟢 [21:30] HPA scaled sprive-backend: 28 → 18 pods
🟢 [22:00] HPA scaled sprive-backend: 18 → 12 pods
No red alerts. The system did exactly what it was designed to do.
Lessons for Your Next Traffic Spike
1. Scale Before You Need To
Don't wait for 80% CPU. Set your HPA to trigger at 40-50%. The cost of running extra pods is nothing compared to the cost of dropped requests.
2. Cache Aggressively
Our 73% cache hit rate meant only 27% of requests touched the database. That's the difference between a 5000 connection database and a 1400 connection one.
3. Make Critical Paths Fast, Everything Else Async
API responses should take under 100ms. Everything else (emails, analytics, notifications) can happen in the background.
4. Load Test at 2x Expected Peak
We expected 500 req/s. We tested at 1500 req/s. We got 970 req/s. That buffer saved us.
5. Automate Database Hygiene
Don't wait for connection exhaustion. Run automated cleanup. Our Lambda kills sleeping connections before they become a problem.
6. Work With What You Have
I still want to migrate to Java. But our 5-year-old Node.js codebase handled 970 req/s because we optimized what we had rather than waiting for a perfect rewrite.
The Morning After
I woke up on February 6th to find:
- Zero P1 incidents
- £627,000 in processed transactions
- Not a single customer complaint about downtime
And by Sunday? Sprive was the #1 Finance app in the UK App Store, ahead of Monzo, Revolut, and every major bank.
 Jinesh Vohra pitching Sprive to the Dragons - moments before the traffic surge began
Jinesh Vohra pitching Sprive to the Dragons - moments before the traffic surge began
The infrastructure held. The team held. And three Dragons (Touker, Deborah, and Peter) had said yes.
The Ultimate Validation
48 hours after Dragons' Den aired, we woke up to this:
 No. 1 on the App Store. Above Monzo. Above Revolut. Above HMRC. This was our moment.
No. 1 on the App Store. Above Monzo. Above Revolut. Above HMRC. This was our moment.
No marketing budget in the world can buy this. Three minutes on national television, an infrastructure that held under pressure, and a product that resonated with millions.
About the Author: Engineering at Sprive, where we help people pay off their mortgages faster. When I'm not handling traffic spikes from national television, I write about distributed systems and fintech infrastructure.
Got questions about scaling for unexpected traffic? Drop a comment below.